Flume is a distributed, scalable, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
In short, Flume is a distributed,Reliable, Scalable, Extensible service to move data from Source to a destination.
Flume helps in aggregating the generated logs from different source (or application service) at different machine (or in nodes of a cluster) that needs to analyze and processed on a Hadoop environment.
Reliable: Fault Tolerance and High Availability [Tunable data reliability levels]
Scalable: Horizontal Scalability of nodes [Can add more collectors to increase availability]
Extensible data model: Can deal with all kind of data/sources [Twitter, Syslog etc]
Flume-NG (Flume1.x) is a major overhaul of Flume-OG (Flume 0.x).
Flume Data flow model Terminology
A Flume data flow is a complete transport from Source to Sink. A Flow is a type of data source like server logs, click streams etc. Following are the components plays a vital role in the flow:
a. Agent b. Event c. Source d. Channel e. Sink f. Interceptors (Optional)
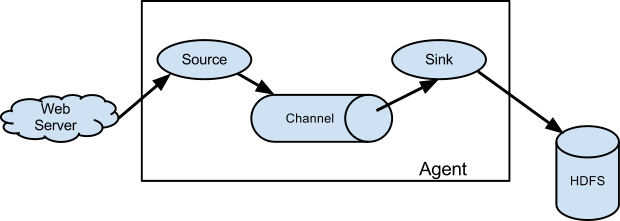
(above image is from Apache flume website, copyrights to them)
Agent
– A Flume agent is a JVM process that hosts the components (Source, Channel, Sink) that allow Events to flow from an external source to a external destination.
Event
– An Event is a unit of data that flows through a one or more Flume agent. The Event flows from Source to Channel to Sink
– An Event comprises of zero or more headers, byte payloads and optional attributes.
– An header is an key-value pair.
– Flume uses a transactional approach to guarantee the reliable delivery of the events.
Source
– A Flume source consumes events from an external source like a web server, 3rd part api twitter.
– The external source sends events to Flume in a recognizable format.
– The external source sends events to Flume in a format that is recognized by the target Flume source
– A source writes Events to one or more channel
Channel
– A received event from Source stores it into one or more passive channels and keeps the event until it’s consumed by a Flume Sink.
– The Channel act as a glue between Source and Sink
– The Channel could be a in-memory (fast, non reliable and non recoverable) or disk based (slow, reliable, recoverable)
Sink
– the sink extracts the event from the channel and puts it in an external repository like the HDFS
– A Sink could be a HDFS-formatted file system or another Agent in the hop or text/console display or could be a null.
Flume Interceptors
-Interceptors are part of Flume’s extensibility model.
-They allow events to be intercept (can be modify/remove) as they pass between a source and a channel, and the developer is Interceptors can be chained together to form a processing pipeline.
– They are similar to Servlet Filter mechanism
Multi Hop Flows
– Flume allows a user to build multi-hop flows where events travel through multiple agents before reaching the final destination. It also allows fan-in and fan-out flows, contextual routing and backup routes (fail-over) for failed hops.
So, in the case of a complex flow, the Sink forwards it to the other Flume source of the next Flume agent (next hop) in the flow.
Fan out flow
– fanning-out is a concept of delivering events to other parts of the Agent during the flow
– Replicating and Multiplexing are two types of Fanning out
– Replicating: Event is written to all the configured channels. This is default type of Fanning out mechanism
– Multiplexing: Event is written to a specific configured channels (E.g. on the basis of certain header key etc)
The External source and Target Flume Source event Format
– Generally the external source sends the event in a format that is recognizable to the Flume source.
– E.g. Avro/Thrift Flume source can be used to receive Avro/Thrift events from Avro/Thrift clients
Flume provides the following out of the box provider for Source, Channels and Sinks:
Source
1 Avro Source (type of log stream)
2 Thrift Source (type of log stream)
3 Exec Source
4 JMS Source: Converter
5 Spooling Directory Source
6 Twitter firehose Source (experimental)
7 Event Deserializers: LINE, AVRO, BlobDeserializer
8 NetCat Source (type of log stream)
9 Sequence Generator Source
10 Syslog Sources (type of log stream): Syslog TCP Source, Multiport Syslog TCP Source, Syslog UDP Source
11 HTTP Source: JSONHandler, BlobHandler
12 Legacy Sources: Avro Legacy Source, Thrift Legacy Source
13 Custom Source
14 Scribe Source
Channel
1. Memory Channel
2. JDBC Channel
3. File Channel
4. Spillable Memory Channel
5. Pseudo Transaction Channel
6. Custom Channel
Sinks
1. HDFS Sink
2. Logger Sink
3. Avro Sink
4. Thrift Sink
5. RC Sink
6. File Roll Sink
7. Null Sink
8. HBaseSinks: HBaseSink, AsyncHBaseSink
9. MorphlineSolrSink
10. ElasticSearchSink
11. Kite Dataset Sink (experimental)
12. Custom Sink
